Evaluate from SDK
This guide explains how to run evaluations programmaticaly from the SDK in agenta. We will do the following:
- Create a test set
- Create and configure an evaluator
- Run an evaluation
- Retrieve the results of evaluations
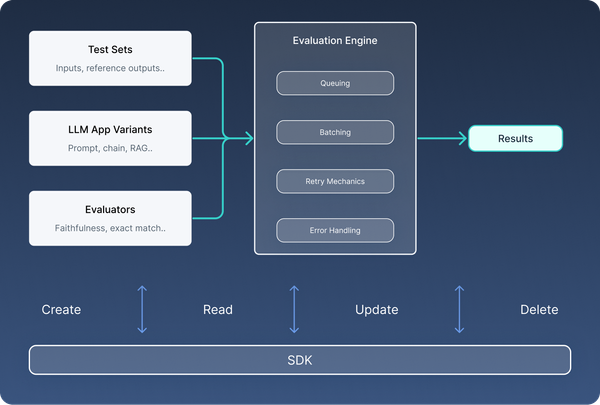
How agenta evaluation works
In agenta, evaluation is a fully managed service . It takes place entirely on our backend, and take care of:
- Queuing and managing evaluation jobs
- Batching LLM app calls to optimize performance and avoid exceeding rate limits.
- Handle retries and errors automatically to ensure robust evaluation runs.
Our evaluation service takes a set of test sets, evaluators, and app variants and runs asynchronous jobs for evaluation.
You can open this guide in a jupyter notebook
1. Setup
-
Create an LLM app and a couple of variants in agenta and install our sdk using
pip install -U agenta. -
Retrieve the application id either from the url.
2. Setup the SDK client
app_id = "667d8cfad1812781f7e375d9"
# You can create the API key under the settings page. If you are using the OSS version, you should keep this as an empty string
api_key = "EUqJGOUu.xxxx"
# Host.
host = "https://cloud.agenta.ai"
# Initialize the client
client = AgentaApi(base_url=host + "/api", api_key=api_key)
3. Create a test set
from agenta.client.backend.types.new_testset import NewTestset
csvdata = [
{"country": "france", "capital": "Paris"},
{"country": "Germany", "capital": "Berlin"}
]
response = client.testsets.create_testset(request=NewTestset(name="test set", csvdata=csvdata))
test_set_id = response.id
4. Create evaluators
Let's create a custom code evaluator that return 1.0 if the first letter of the app output is uppercase
code_snippet = """
from typing import Dict
def evaluate(
app_params: Dict[str, str],
inputs: Dict[str, str],
output: str, # output of the llm app
datapoint: Dict[str, str] # contains the testset row
) -> float:
if output and output[0].isupper():
return 1.0
else:
return 0.0
"""
response = client.evaluators.create_new_evaluator_config(app_id=app_id, name="capital_letter_evaluator", evaluator_key="auto_custom_code_run", settings_values={"code": code_snippet})
letter_match_eval_id = response.id
5. Run an evaluation
First let's grab the first variants in the app
response = client.apps.list_app_variants(app_id=app_id)
print(response)
myvariant_id = response[0].variant_id
Then , let's start the evaluation jobs
from agenta.client.backend.types.llm_run_rate_limit import LlmRunRateLimit
rate_limit_config = LlmRunRateLimit(
batch_size=10, # number of rows to call in parallel
max_retries=3, # max number of time to retry a failed llm call
retry_delay=2, # delay before retrying a failed llm call
delay_between_batches=5, # delay between batches
)
response = client.evaluations.create_evaluation(app_id=app_id,
variant_ids=[myvariant_id],
testset_id=test_set_id,
evaluators_configs=[letter_match_eval_id],
rate_limit=rate_limit_config)
print(response)
Now we can check for the status of the job
client.evaluations.fetch_evaluation_status('667d98fbd1812781f7e3761a')
As soon as it is done, we can fetch the overall results
response = client.evaluations.fetch_evaluation_results('667d98fbd1812781f7e3761a')
results = [(evaluator["evaluator_config"]["name"], evaluator["result"]) for evaluator in response["results"]]
and the detailed results
client.evaluations.fetch_evaluation_scenarios(evaluations_ids='667d98fbd1812781f7e3761a')